Ready for the web
Splout allows serving an arbitrarily big dataset with high QPS
rates and at the same time provides full SQL query syntax.
Splout is appropriated for web page serving, many low latency lookups, scenarios
such as mobile or web applications with demanding performance.
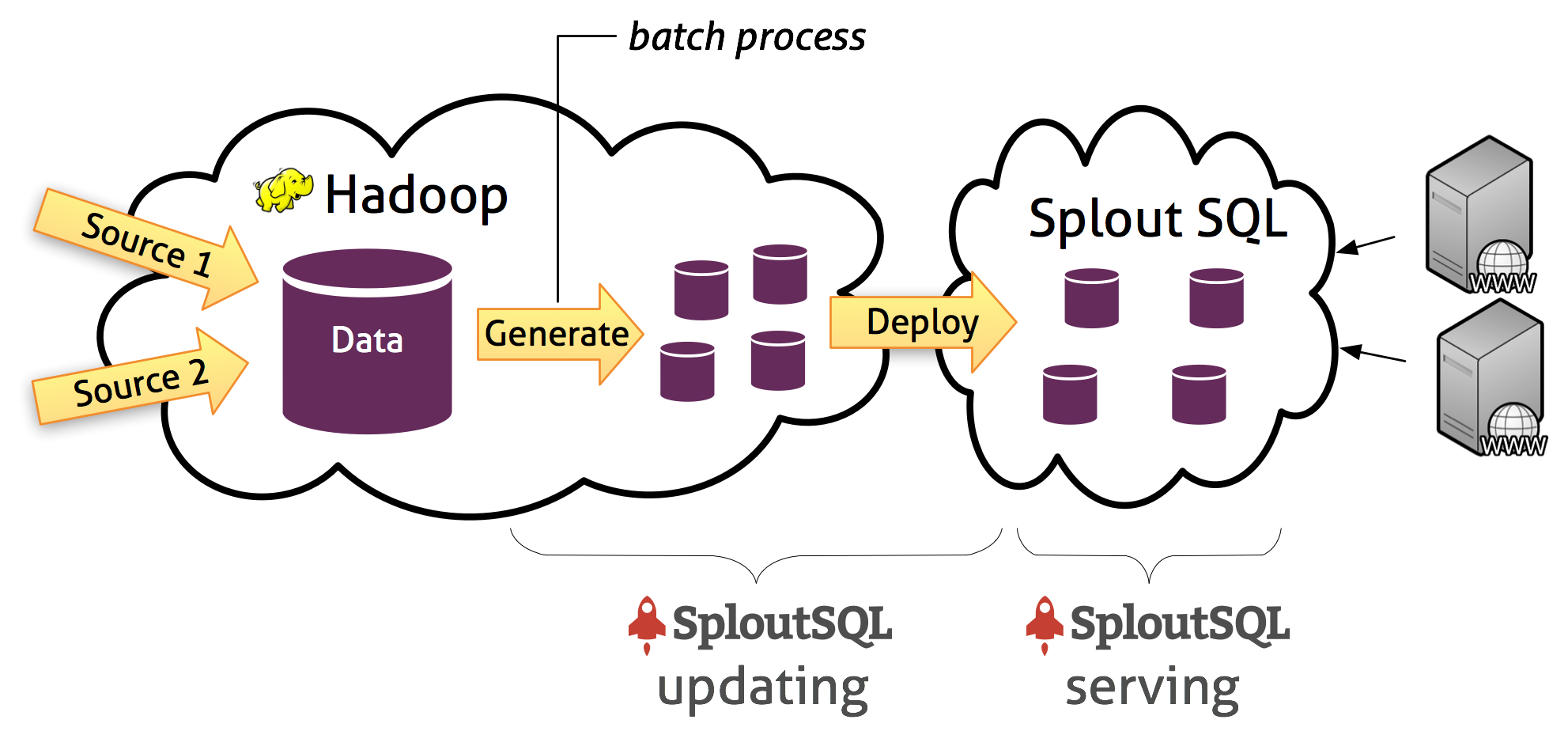
Plays well with Hadoop
Splout uses
Pangool for
decoupling database
creation from database serving. The data is always
optimally indexed and
evenly distributed among partitions, plus updating all the data at once doesn’t affect the serving of
the datasets. Splout can import data directly from
Hive, Cascading or Pig.
Scalable
Splout is horizontally scalable. You can increase throughput linearly by just adding
more machines.
Splout is replicated for failover. Splout transparently replicates your dataset for
properly handling failover scenarios such as network splits or hardware corruption.